Gertrude Stein diceva:”Rose is a rose is a rose is a rose“. Ecco un bell’esempio che mostra quanto possa essere complicato il linguaggio umano. La frase è ambigua e consente molteplici interpretazioni. Stein spiegò il significato come segue: “il poeta poteva usare il nome della cosa e la cosa era davvero lì”.
Ciò che invece ci chiediamo oggi è se è veramente possibile creare un algoritmo intelligente che sia davvero in grado di comprendere il significato del linguaggio umano.

In questo articolo cercheremo di fare luce sul modo in cui i motori di ricerca trovano i documenti relativi alla domanda fatta loro da un utente. Mostreremo anche alcuni approcci che possono essere usati per estrarre il significato semantico da una proposta.
Ma andiamo con ordine ripercorrendo, in parte, la storia di Google. Prima che il più potente motore di ricerca al mondo introducesse RankBrain, la ricerca semantica e l’apprendimento automatico di tutte le cose, compresa la vita dei SEO, era certamente più facile.
A complicare le cose ci sono i portavoce di Google che condividono informazioni spesso oscure sui segnali di qualità, ripetendo il più che famoso mantra “Content is king“.
Ci sono due campi dell’informatica che sono l’elaborazione del linguaggio naturale e il recupero delle informazioni, che affrontano una serie enorme di problemi legati alla SEO. Esistono algoritmi ben documentati per la classificazione del testo e il recupero di documenti rilevanti alla risposta della singola domanda dell’utente.
Se siete interessati ad apprendere concetti un po’ più accademici dietro la “ricerca semantica”, “ricerca per parole chiave”, “ottimizzazione dei contenuti” e altre parole chiave SEO, continuate a leggere! Tuttavia, siate consapevoli che questo articolo non vi darà alcuna ricetta magica per la SEO on-page, ma piuttosto proverà a rispondere ad alcune delle domande su alcuni dei tanti “perché” che probabilmente avete.
Che cosa è una parola
La parola è il più piccolo elemento costitutivo del significato e un punto di partenza logico del nostro viaggio. Proviamo a scoprire come le parole sono rappresentate nel mondo dell’informatica.
Nel caso più semplice, un programma per computer vede un testo come una sequenza di caratteri alfanumerici e punteggiatura. Questa è una cosiddetta rappresentazione grezza.
Se prendiamo ad esempio la frase “I programmi del programmatore erano stati programmati”, le parole separate possono essere delimitate da spazi o punteggiatura. Come risultato, otteniamo una lista di token. Si noti che a questo punto consideriamo i caratteri di punteggiatura come token distinti.
Il primo token della lista pone un dilemma. Come dovremmo trattare i caratteri maiuscoli? Dovremmo cambiare tutti i caratteri in lettere minuscole? Sembra ragionevole optare per questa scelta. Dopo tutto, “I” e “i” rappresentano ovviamente la stessa parola, vale a dire, l’articolo determinativo.
In inglese alcuni aspetti grammaticali e no si complicano. Che dire ad esempio di “Smith” e “smith”? Può essere un nome proprio, un sostantivo con il significato di “qualcuno che fa e ripara cose fatte di ferro”, o lo stesso sostantivo all’inizio di una frase.
Riprendiamo la frase sopra citata: “I programmi del programmatore erano stati programmati”. Le parole possono avere forme diverse. Per esempio, il token “programmi” del nostro esempio è in realtà una forma plurale del sostantivo “programma”. “Programmati” è il passato prossimo del verbo “programmare”.
Le forme iniziali delle parole o le forme che rappresentano le parole in un dizionario sono chiamate lemmi. E un ulteriore passo logico è quello di rappresentare le parole con i rispettivi lemmi.
Probabilmente avete sentito dire che i motori di ricerca utilizzano le liste di parole stop per preelaborare i testi di input. Una lista di stop word è un insieme di token che vengono rimossi da un testo. Le parole di stop possono includere parole funzionali e punteggiatura. Le parole funzionali sono parole che non hanno un significato indipendente, per esempio, verbi ausiliari o pronomi.
Ma se prendiamo la frase “Il programma dei programmi è stato programmato” e togliamo le parole funzionali dalla frase, come risultato, l’enunciato iniziale include solo parole di contenuto (le parole che hanno un significato semantico). Tuttavia, non c’è modo di dire che il programma in questione è in qualche modo legato al programmatore.
Un ulteriore passo in avanti lo faccio quando una parola può essere rappresentata dal suo stelo. Uno stelo è una parte di una parola alla quale normalmente ci colleghiamo. Ed ancora una volta l’inglese ci viene incontro. Pensiamo a come in inglese si dice programmatore. Attaccando il suffisso “-er”otteniamo la parola programmer (con il significato di qualcuno che compie un’azione) al “programma” dello stelo.
Ecco quindi che abbiamo individuato 3 modi tipici di rappresentare le parole:
- Token
- Lemmi
- Steli
Togliendo le parole funzionali o convertendo le parole in minuscole, queste rappresentazioni e le loro combinazioni vengono utilizzate a seconda dell’effettivo compito di elaborazione della lingua. Per esempio, è irragionevole togliere le parole funzionali se abbiamo bisogno di differenziare i testi in inglese e francese. Se abbiamo bisogno di individuare i nomi propri in un testo, è ragionevole conservare il carattere originale e così via.
Un’ultima annotazione utile da sapere è che ci sono alcune unità più grandi di una parola ma più piccole di una frase.
Le unità linguistiche discusse sopra sono gli elementi costitutivi di strutture più grandi, come i documenti che discuteremo più avanti.
Appunti SEO take-away
È importante capire come e perché si suddivide una frase in unità perché queste unità fanno parte di una metrica che tutti i SEO usano o della quale sono consapevoli, cioè la “keyword density“.
Molti SEO rispettabili si oppongono a questo concetto dicendo che “la densità delle parole chiave non viene usata”, proponendo TF-IDF come alternativa migliore in quanto legata alla ricerca semantica.
Nell’articolo mostreremo ulteriormente che sia il conteggio delle parole grezze che quello ponderato (TF-IDF) possono essere usati sia per la ricerca lessicale che semantica.
La keyword density è una metrica semplice e maneggevole che ha tutto il diritto di esistere. Basta non esserne ossessionati.
Vale anche la pena di tenere presente che le forme grammaticali delle parole sono molto probabilmente trattate dai motori di ricerca come lo stesso tipo di parola, quindi potrebbe essere di scarsa utilità cercare di “ottimizzare” una pagina web, ad esempio, per forme singolari e plurali della stessa parola chiave.
Che cosa è il bag-of-words
Il bag-of-words è un modello utilizzato nell’elaborazione del linguaggio naturale per rappresentare un testo. Sebbene il concetto risalga agli anni ’50, viene ancora utilizzato per la classificazione del testo e il recupero delle informazioni (cioè i motori di ricerca).
Useremo il bag-of-words per mostrare come i motori di ricerca possono trovare un documento rilevante da un insieme in risposta a una ricerca.
Se vogliamo rappresentare un testo come bagaglio di parole, contiamo solo il numero di volte che ogni parola appare nel testo ed elenchiamo questi conteggi (in termini matematici, si tratta di un vettore). Prima del conteggio, si possono applicare le tecniche di pre elaborazione descritte nella parte precedente dell’articolo.
Come risultato, si perdono tutte le informazioni sulla struttura del testo, la sintassi e la grammatica del testo.
I programmi del programmatore erano stati programmati
La: 1, programmatore: 1, ‘s: 1, programmi: 1, erano: 1, stati: 1, programmati: 1 } o
[1, 1, 1, 1, 1, 1, 1]
programma programmatore programmati
Programmatore: 1, programma: 1 programmati: 1} o
[1, 2]
Non c’è molta utilità pratica nel rappresentare un testo separato come elenco di cifre. Tuttavia, se abbiamo una raccolta di documenti (ad esempio tutte le pagine web indicizzate da un certo motore di ricerca), possiamo costruire un cosiddetto modello vettoriale spaziale a partire dai testi disponibili.
Il termine può sembrare spaventoso, ma in realtà l’idea è piuttosto semplice. Immaginate un foglio di calcolo in cui ogni colonna rappresenta il sacco di parole di un testo (vettore di testo), e ogni riga rappresenta una parola della collezione di questi testi (parola vettore). Il numero di colonne equivale al numero di documenti della collezione. Il numero di righe equivale al numero di parole uniche che si trovano in tutta la collezione di documenti.
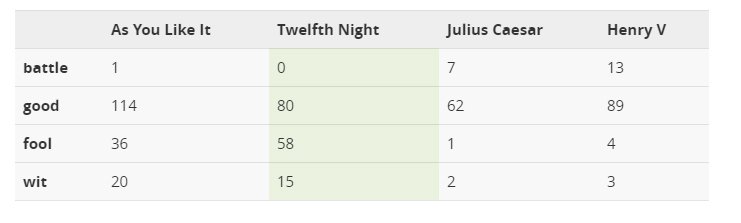
Il valore nell’intersezione di ogni riga e colonna è il numero di volte che la parola corrispondente appare nel testo corrispondente. Il foglio di calcolo sottostante rappresenta lo spazio vettoriale per alcune opere teatrali di Shakespeare. Per semplicità, utilizziamo solo quattro parole.
Una cosa interessante dei vettori è che possiamo misurare la distanza o l’angolo tra di loro. Più piccola è la distanza o l’angolo, più “simili” sono i vettori e i documenti che essi rappresentano. Il valore risultante varia da 0 a 1. Più alto è il valore, più i documenti sono simili.
Come fare per trovare un documento rilevante
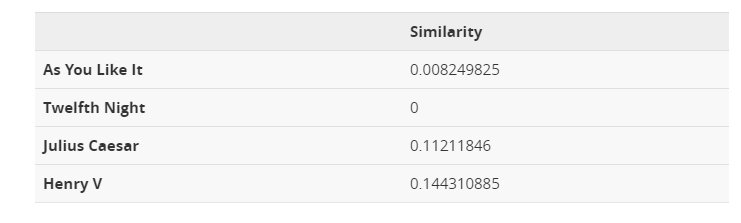
Ora che abbiamo abbastanza informazioni per spiegare come si può trovare in un gruppo un documento rilevante per una ricerca possiamo prendere come esempio la domanda fatta da un utente sta cercando “battaglia di Agincourt”. Questo è un breve documento che può essere incorporato nello spazio vettoriale dell’esempio precedente. Possiamo quindi calcolare la somiglianza della query di ricerca con ogni documento del gruppo. I risultati sono riportati nella tabella sottostante. Si può notare che Enrico V è il miglior abbinamento per la ricerca. Non c’è da stupirsi perché la parola “battaglia” compare più spesso in questo testo e quindi il documento può essere considerato più rilevante per la query. Inoltre, si noti che non è necessario che tutte le parole di una ricerca siano presenti nel testo.
Vi sono degli ovvi inconvenienti di un approccio così semplicistico, perché prima di tutto è vulnerabile al keyword stuffing. Si può aumentare sostanzialmente la rilevanza di un documento per una ricerca semplicemente ripetendo la parola richiesta tante volte quante sono necessarie per battere i documenti concorrenti.
Pensiamo alla rappresentazione del “bag-of-words” per il seguente documento:
Sono rimasto impressionato, non era male!
Non sono rimasto impressionato, è stato brutto!
La “bag-of-words” sarà assolutamente identica, anche se hanno significati diversi. Ricordate, che il modello bag-of-words rimuove tutta la struttura dei documenti sottostanti.
Il modello bag-of-words con frequenza di parola non è la misura migliore. È orientato verso parole molto frequenti e non è discriminante.
TF-IDF e la legge di Zipf
La legge di Zipf afferma che, dato un ampio campione di parole usate, la frequenza di ogni parola è inversamente proporzionale al suo rango nella tabella delle frequenze. Quindi la parola numero N ha una frequenza proporzionale a 1/N. Come risultato, c’è un modello interessante nelle lingue naturali. Il 18% (circa) delle parole più frequentemente usate rappresenta oltre l’80% delle occorrenze delle parole. Significa che alcune parole sono usate spesso e molte parole sono usate raramente.
Le parole frequenti compaiono in molti testi e di conseguenza tali parole rendono più difficile differenziare i testi rappresentati come “bag-of-words”. Inoltre, le parole più frequenti sono spesso parole funzionali senza significato semantico. Non possono descrivere l’argomento di un testo.
Queste sono le 10 parole più frequenti in inglese.
Queste sono le 10 parole più frequenti in inglese.
il
essere
a
di
e
a
in
il quale
avere
I
Possiamo applicare la ponderazione TF-IDF (term frequency – inverse document frequency) per diminuire il peso delle parole che sono usate frequentemente nella raccolta di testi. Il punteggio TF-IDF è calcolato con la seguente formula:
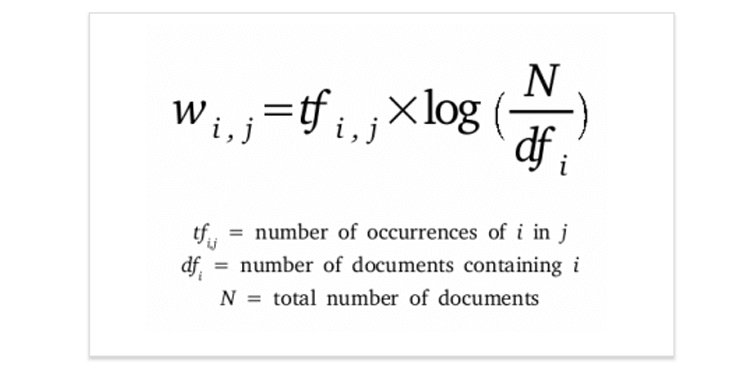
Dove il primo componente è il termine frequenza – la frequenza della parola nel documento. E il secondo componente è la frequenza inversa del documento. È il numero di documenti in una gruppo diviso per la frequenza del documento di una parola, che è il numero totale di documenti in cui la parola appare. Il secondo componente viene utilizzato per dare un peso maggiore alle parole che compaiono solo in pochi documenti del gruppo.
Nella tabella sottostante sono riportati alcuni valori IDF per alcune parole delle opere teatrali di Shakespeare, che vanno da parole estremamente informative che si verificano in un solo personaggio come Romeo, a quelle che sono così comuni da essere completamente non discriminatorie in quanto si verificano in tutti i 37 ruoli, come “buono” o “dolce”.
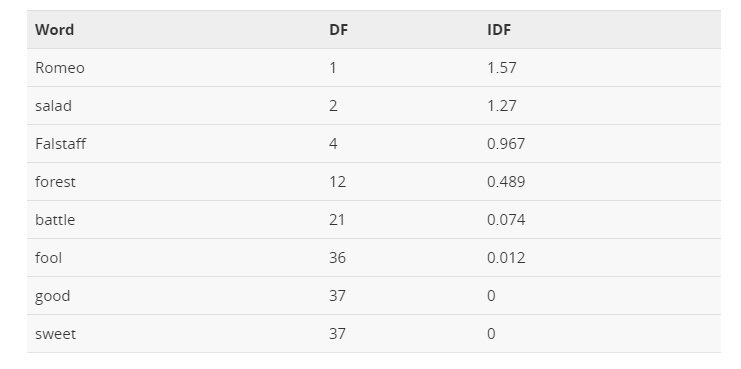
Appunti SEO take-away
- Abbiamo qualche dubbio che il modello “bag-of-words” sia oggi utilizzato nei motori di ricerca commerciali. Ci sono modelli che catturano meglio la struttura del testo e tengono conto di più caratteristiche linguistiche, ma l’idea di base rimane la stessa. I documenti e le query di ricerca si trasformano in vettori e la somiglianza o distanza tra i vettori viene utilizzata come misura di rilevanza.
- Questo modello permette di capire come funziona la ricerca lessicale rispetto alla ricerca semantica. Per la ricerca lessicale è essenziale che un documento contenga le parole menzionate in una ricerca. Mentre questo non è necessario per la ricerca semantica.
- La legge di Zipf dimostra che esistono proporzioni prevedibili in un testo scritto in linguaggio naturale. Le deviazioni dalle proporzioni tipiche sono facili da individuare. Quindi, non è difficile segnalare un testo sovra-ottimizzato che è “innaturale”.
- Lo schema di ponderazione TF-IDF non è una chiave nel magico mondo della ricerca semantica. Con TF-IDF applicato a un modello, le caratteristiche del documento etichettate dalle parole del contenuto hanno un peso maggiore nel vettore del documento. Ed è interessante interpretare il fenomeno come qualcosa di “semantico”.
Che cosa è la ricerca semantica
La ricerca semantica è una delle parola d’ordine nella comunità SEO già dal 2013. La ricerca semantica denota la ricerca con significato, come distinta dalla ricerca lessicale dove il motore di ricerca cerca corrispondenze letterali delle parole di ricerca o varianti di esse, senza comprendere il significato complessivo della ricerca.
Ma come può un motore di ricerca imparare il significato di una parola? C’è un problema di alto livello ancora più difficile. Come possiamo rappresentare il significato in modo che un programma per computer possa capirlo e utilizzarlo praticamente?
Il concetto chiave che aiuta a rispondere a queste domande è l’ipotesi distributiva che è stata formulata per la prima volta già negli anni Cinquanta. I linguisti hanno notato che parole con significato simile tendono a verificarsi nello stesso ambiente (cioè vicino alle stesse parole) con la quantità di differenza di significato tra due parole che corrisponde all’incirca alla quantità di differenza nel loro ambiente.
Ecco un semplice esempio. Proviamo a leggere le seguenti frasi senza avere idea di cosa sia uno scampo:
Gli scampi sono considerati una prelibatezza.
Gli scampi hanno carne bianca carnosa nella coda e il corpo è succoso, leggermente dolce e magro.
Quando scegliamo gli scampi, prestiamo attenzione al colore arancione chiaro.
Ora associamo i seguenti elementi presupponendo che maggior parte dei lettori sappia cos’è un gamberetto:
I gamberetti sono una prelibatezza che si abbina bene con il vino bianco e la salsa al burro.
Tenera carne di gamberi può essere aggiunta alla pasta.
Quando bolliti, i gamberetti cambiano colore in rosso.
Il fatto che lo scampo avvenga con parole come delicatezza, carne e pasta potrebbe suggerire che lo scampo è una sorta di crostaceo commestibile simile in qualche modo a un gamberetto. Così si può definire una parola in base all’ambiente in cui si trova nell’uso della lingua, come l’insieme dei contesti in cui si trova, le parole vicine.
Come possiamo trasformare queste osservazioni in qualcosa di significativo per un programma per computer?
Possiamo costruire un modello simile al “bag-of-words”. Ma invece di documenti, etichetteremo le colonne con le parole.Comunemente possiamo usare piccoli contesti di circa quattro parole intorno a una parola di destinazione. In questo caso, ogni cella del modello rappresenta il numero di volte che la parola della colonna si verifica in una finestra di contesto (ad esempio, più meno quattro parole) intorno alla parola di riga. Consideriamo queste finestre a quattro parole (l’esempio è preso dal libro Jurafsky & Martin, Speech and Language Processing):
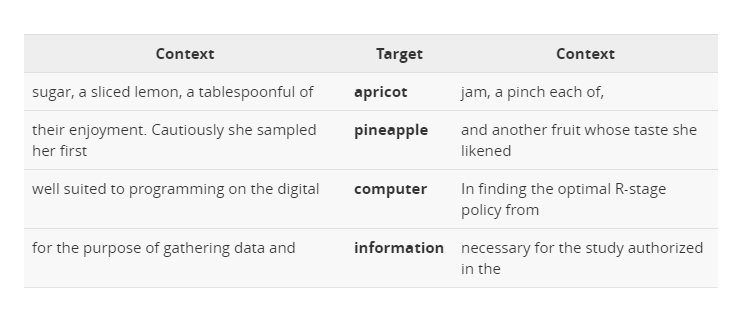
Per ogni parola, raccogliamo i conteggi (dalle finestre intorno ad ogni occorrenza) delle occorrenze delle parole di contesto. E otteniamo la matrice di co-occorrenza parola-parola simile a quella che abbiamo già visto in precedenza. Si può notare che “digitale” e “informazione” sono più simili tra loro che non ad “apricot” (albicocca). Si noti che il conteggio delle parole può essere sostituito da altre metriche come l’informazione reciproca puntuale.
Ogni parola e la sua semantica sono rappresentate con un vettore. Le proprietà semantiche di ogni parola sono determinate dai suoi vicini, cioè dai contesti tipici in cui la parola appare. Un tale modello può facilmente catturare la sinonimia e la relazione tra parole. I vettori di due parole simili appariranno vicini l’uno all’altro. E i vettori delle parole che appaiono nello stesso campo tematico formeranno dei cluster nello spazio.
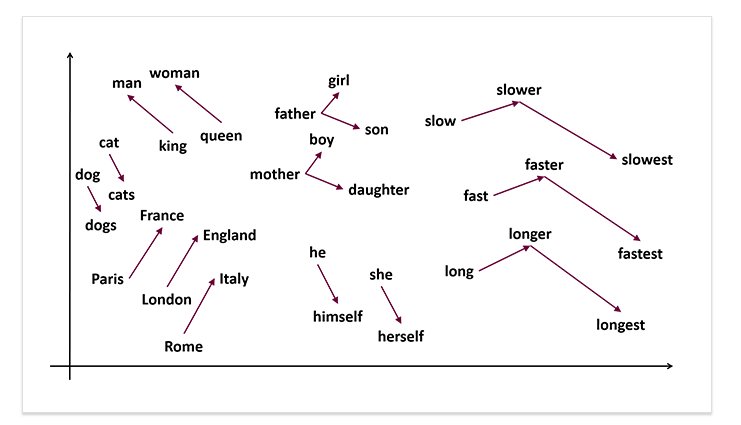
Come si sarà capito non c’è magia dietro la ricerca semantica. La differenza concettuale è che le parole sono rappresentate come incorporazione vettoriale ma non come elementi lessicali (stringhe di caratteri).
Appunti SEO take-away
I modelli semantici sono bravi a catturare sinonimi, parole correlate e cornici semantiche. Una cornice semantica è un insieme di parole che denotano prospettive o partecipanti ad un particolare tipo di evento. Per esempio, la cornice semantica “le 5 è l’ora del tea” può includere tradizione, tè, tazza, bollitore, cucchiaio, zucchero, bevanda, birra, ecc.
Quando si creano nuovi contenuti può essere utile pensare alla dimensione delle cornici semantiche. Cioè tenete a mente la cornice semantica per cui volete che la vostra pagina sia classificata, non una parola chiave particolare.
La filatura dei contenuti ha probabilmente poco o nessun effetto. Parole sinonimi come “piatto” e “appartamento” avranno vettori molto simili. La rotazione dei sinonimi produrrà un testo con un’impronta molto vicina alla variante iniziale.
I motori di ricerca sono diventati migliori nell’estrarre informazioni dalle pagine web, ma è sempre una buona idea dare loro suggerimenti utilizzando markup di dati strutturati.
La linguistica computazionale è una scienza emozionante e in rapida evoluzione. I concetti presentati in questo articolo non sono nuovi o rivoluzionari. Ma sono piuttosto semplici e aiutano ad ottenere una visione di base di alto livello sul campo problematico. Se volete saperne di più su come funzionano effettivamente i motori di ricerca, vi consigliamo di leggere il libro “Introduction to Information Retrieval” di Manning, Raghavan, & Schütze, acquistabile anche online.
[via link-assistant.com]