
Ascolta.
Questo non è l’ennesimo articolo sull’AI scritto per fare views. Qui hai le 10 domande che contano davvero. Quelle che chiudono la bocca all’hype e ti fanno prendere decisioni oggi, non tra sei mesi.
Ogni domanda ha due chiavi:
- Risposta tecnica (livello Master in nerdologia computazionale applicata): come funziona per davvero, cosa scegliere, quali limiti.
- In parole semplici (livello Università della vita): analogie, esempi concreti, modo giusto per spiegarlo a clienti, team e board.
Cosa trovi dentro?
Il necessario, senza fronzoli: cos’è l’AI, come funziona, debole vs generale, AI vs ML vs DL (matrioska), perché ora, limiti reali, come apprendono i modelli, regole vs AI moderna, quando nasce la disciplina, l’AI pensa come noi?
Leggi perché ti serve: smonti confusione, eviti errori costosi, parli la lingua giusta con tecnici e decisori, porti a casa scelte operative.
Vuoi risultati? Inizia dalla prima domanda.
Il resto è rumore.
1. Che cos’è l’intelligenza artificiale (AI) e come la si può definire in modo semplice?
Risposta tecnica:
L’intelligenza artificiale (AI) è un ramo dell’informatica che crea sistemi in grado di svolgere compiti che normalmente richiederebbero l’intelligenza umana. In termini formali, un sistema AI è un software (o insieme di algoritmi) progettato per percepire dati dal suo ambiente, elaborarli attraverso modelli matematici e agire di conseguenza o fornire decisioni imitando processi cognitivi umani.
Ad esempio, un’AI può analizzare grandi quantità di dati, riconoscere pattern ricorrenti e utilizzare queste regolarità per prendere decisioni o fare previsioni.
A differenza del software tradizionale, in cui ogni passo è esplicitamente programmato, un’AI spesso apprende dai dati: ovvero migliora le proprie prestazioni man mano che “vede” più esempi, grazie a metodi di apprendimento automatico.
In parole tecniche, potremmo definire l’AI come “la scienza e l’ingegneria di creare macchine intelligenti, specialmente programmi di computer capaci di ragionare, apprendere e risolvere problemi”.
È importante notare che esistono vari approcci e sottocampi dell’AI (come il machine learning, le reti neurali, etc.), ma tutti condividono l’obiettivo di simulare forme di intelligenza.
Ad esempio, AI simbolica e AI basata su apprendimento sono due paradigmi diversi, ma entrambi rientrano nella definizione generale. In sintesi, dal punto di vista tecnico l’AI si riferisce a sistemi computazionali capaci di prendere decisioni o eseguire azioni ritenute “intelligenti” perché simili a ciò che farebbe un essere umano in circostanze analoghe.
In parole semplici:
L’intelligenza artificiale è, in poche parole, la capacità dei computer di “pensare” un po’ come facciamo noi umani.
Immagina di insegnare a un computer come riconoscere un gatto in una foto: invece di dirgli tu “questa combinazione di pixel è un gatto”, gli mostri tante foto di gatti finché il computer impara da solo a capire quali caratteristiche visive definiscono un gatto.
Proprio come una persona impara da esperienza ed esempi, un’AI impara dai dati. Quindi potremmo definire l’AI come un computer che impara e prende decisioni, non perché qualcuno abbia scritto tutte le istruzioni passo passo, ma perché ha capito il modello dai dati precedenti.
Ad esempio, l’AI è ciò che permette al tuo smartphone di suggerirti la parola successiva mentre scrivi un messaggio: ha “osservato” tantissimi testi e ha imparato quali parole di solito seguono altre. In definitiva, l’AI è come un aiutante intelligente e instancabile: riesce a trovare informazioni e schemi nascosti tra milioni di dati molto più velocemente di noi, e usa queste conoscenze per svolgere compiti che vanno dal riconoscere volti in una foto al consigliarti il prossimo film da guardare.
Se la programmazione tradizionale è come dare istruzioni fisse a un computer, l’AI è come insegnargli a imparare da sé ciò che deve fare.
2. Come funziona l’AI e cosa rende un sistema “intelligente”?
Risposta tecnica:
Il funzionamento interno di un sistema di intelligenza artificiale combina algoritmi matematici e dati su larga scala per simulare capacità cognitive. In pratica, possiamo suddividere il funzionamento dell’AI in tre fasi principali:
- (a) Acquisizione dei dati: l’AI riceve input dal mondo esterno sotto forma di dati (numeri, testo, immagini, audio, ecc.). Ad esempio, un’AI per il riconoscimento di immagini acquisisce i pixel di una fotografia.
- (b) Elaborazione/Apprendimento: attraverso algoritmi (cioè procedure matematiche), il sistema analizza questi dati e adatta i propri parametri interni. Durante la fase di addestramento, l’algoritmo modifica iterativamente i suoi parametri (detti pesi, nel caso di una rete neurale) per ridurre l’errore tra le decisioni prese e i risultati attesi. Questo avviene tipicamente con metodi come la discesa del gradiente e la retropropagazione dell’errore, che consentono al modello di imparare dai propri errori. L’aspetto cruciale qui è che il sistema non segue soltanto istruzioni fisse, ma aggiusta i propri calcoli in base ai dati, “migliorando” man mano le sue prestazioni.
- (c) Decisione/Azione: una volta allenato, l’AI utilizza i pattern appresi per dare un output intelligente, come classificare un’immagine (“gatto” vs “cane”), rispondere a una domanda o effettuare una predizione. Un sistema è considerato “intelligente” quando riesce a generalizzare ciò che ha imparato a situazioni nuove.
Ad esempio, un modello AI addestrato su migliaia di radiografie con esempi di tumori sarà in grado di identificare un tumore su una radiografia che non ha mai visto prima: ciò grazie al fatto che ha catturato le caratteristiche generali di un tumore attraverso l’addestramento.
In sintesi, a rendere un sistema davvero intelligente è la capacità di automigliorarsi (learn from data) e di adattarsi all’incertezza – cioè prendere decisioni corrette anche in situazioni non identiche a quelle viste in fase di addestramento, mostrando quindi un comportamento flessibile simile a quello umano.
In parole semplici:
Un’AI funziona un po’ come una persona che impara un nuovo mestiere: prima assorbe tante informazioni, poi le rielabora per capire come svolgere il compito e infine mette in pratica ciò che ha imparato. Ad esempio, immagina di dover insegnare a un bambino a riconoscere gli animali: gli mostri tante foto di cani e gatti (fase di acquisizione dati), lui pian piano coglie le differenze – per esempio nota che i cani di solito sono più grandi e hanno certe forme – (fase di elaborazione/apprendimento) e infine quando vede un animale nuovo prova a dire se è cane o gatto basandosi su ciò che ha capito (fase di decisione).
Un sistema AI fa qualcosa di simile ma con la matematica: prende tantissimi dati come input, trova schemi ricorrenti al loro interno, e poi li usa per dare risposte. Per renderlo concreto: come fa un’assistente vocale a capire la tua voce? Per prima cosa “ascolta” l’audio (onde sonore) e lo converte in dati. Poi, grazie a modelli addestrati in precedenza, riconosce i pattern audio che corrispondono a parole e frasi. Infine, interpreta la frase e ti fornisce una risposta (ad esempio, se hai chiesto “che tempo fa?”, l’AI cercherà online e ti leggerà il meteo). Un sistema sembra intelligente quando riesce a cavarsela in situazioni nuove, non perché qualcuno abbia previsto ogni scenario, ma perché ha imparato le regole generali da tanti esempi.
In breve, l’AI imita alcuni meccanismi del pensiero: impara dagli esempi e applica ciò che ha appreso per risolvere problemi – proprio questo lo fa apparire “intelligente” ai nostri occhi.
3. Cosa sono l’AI “debole” e l’AI “generale”, e in cosa differiscono?
Risposta tecnica:
Nel campo dell’intelligenza artificiale si distingue spesso tra AI Debole (Narrow AI) e AI Generale (General AI).
L’AI Debole, detta anche AI ristretta o debole, indica sistemi progettati e addestrati per svolgere uno specifico compito o un insieme limitato di compiti. Sono estremamente bravi in quello che fanno, spesso superando di molto la performance umana in quell’ambito ristretto, ma non possiedono una comprensione ampia o adattabile al di fuori di esso.
Un esempio: un modello di riconoscimento facciale può identificare volti con alta precisione, ma non può improvvisamente imparare a giocare a scacchi senza essere riprogrammato o ri-addestrato su quel nuovo compito. In altre parole, l’AI debole “eccelle in un solo dominio”. Al contrario, l’AI Generale (chiamata anche Strong AI o AI forte) si riferisce a un’ipotetica intelligenza artificiale con capacità cognitive generali al livello umano.
Un’AI generale sarebbe in grado di capire, imparare e applicare l’intelligenza a qualsiasi problema o attività intellettuale, proprio come fa un essere umano. Ciò significa avere versatilità: oggi un essere umano può cucinare, domani imparare a suonare uno strumento e dopodomani risolvere un problema di matematica – il tutto usando la stessa “intelligenza generale”.
Un AI generale dovrebbe possedere una flessibilità simile. Al momento, non esistono sistemi di AI generale reali: tutte le AI odierne rientrano nel campo delle AI deboli, specializzate in compiti specifici.
Ad esempio, i moderni assistenti vocali o i modelli come ChatGPT sono molto avanzati in un ambito (linguistico), ma comunque non hanno coscienza o comprensione ampia come un umano – mancano di alcune capacità trasversali e di vero senso comune.
Infine, si parla talvolta anche di Superintelligenza: un livello ipotetico ancora superiore, in cui un’intelligenza artificiale superi di gran lunga l’intelligenza umana in praticamente ogni settore (scientifico, creativo, sociale, ecc.).
Questa è una categoria teorica: lo stato dell’arte attuale dell’AI è confinato all’AI debole; l’AI generale è un obiettivo non ancora raggiunto, e la superintelligenza è oggetto di speculazioni e studi teorici sul lungo termine.
In parole semplici:
La differenza tra AI debole e AI generale è un po’ come quella tra uno specialista e un tuttofare. Un’AI “debole” è come un campione mondiale di scacchi che però sa fare solo quello: gioca a scacchi in modo incredibile, ma se gli chiedi di guidare un’auto o scrivere una poesia, non sa da dove cominciare.
Oggi tutte le AI che usiamo sono di questo tipo: molto brave in una cosa specifica, ma incapaci di uscire dal seminato. Per esempio, il filtro antispam della tua email è un’AI debole – sa riconoscere le email indesiderate analizzando il testo, ma non può consigliarti cosa guardare su Netflix.
Invece l’AI “generale” sarebbe una specie di mente artificiale universale, capace di imparare qualsiasi cosa e svolgere qualunque compito intellettuale, un po’ come una persona. Sarebbe l’AI che può ragionare e capire davvero il mondo al nostro livello, passando da un problema all’altro agilmente. Questo è il tipo di intelligenza artificiale che vediamo nei film di fantascienza: robot che pensano, conversano, cucinano, provano emozioni (o almeno sembrano).
Ma nella realtà questa AI generale ancora non esiste.
Quando senti parlare di supercomputer o algoritmi di AI oggi, si tratta di intelligenze ristrette: ad esempio, un programma che traduce lingue non sa guidare una macchina, un’AI che diagnostica malattie da radiografie non sa intrattenere una conversazione su Shakespeare.
Ognuno ha il suo “cervello artificiale” tarato su uno scopo preciso. Riassumendo: l’AI debole è come un attrezzo specializzato, molto affilato ma monotasking; l’AI generale sarebbe come un coltellino svizzero intelligentissimo, capace di adattarsi a qualsiasi cosa – un traguardo che gli scienziati non hanno ancora raggiunto (e ci vorranno probabilmente molti anni, se mai accadrà davvero).
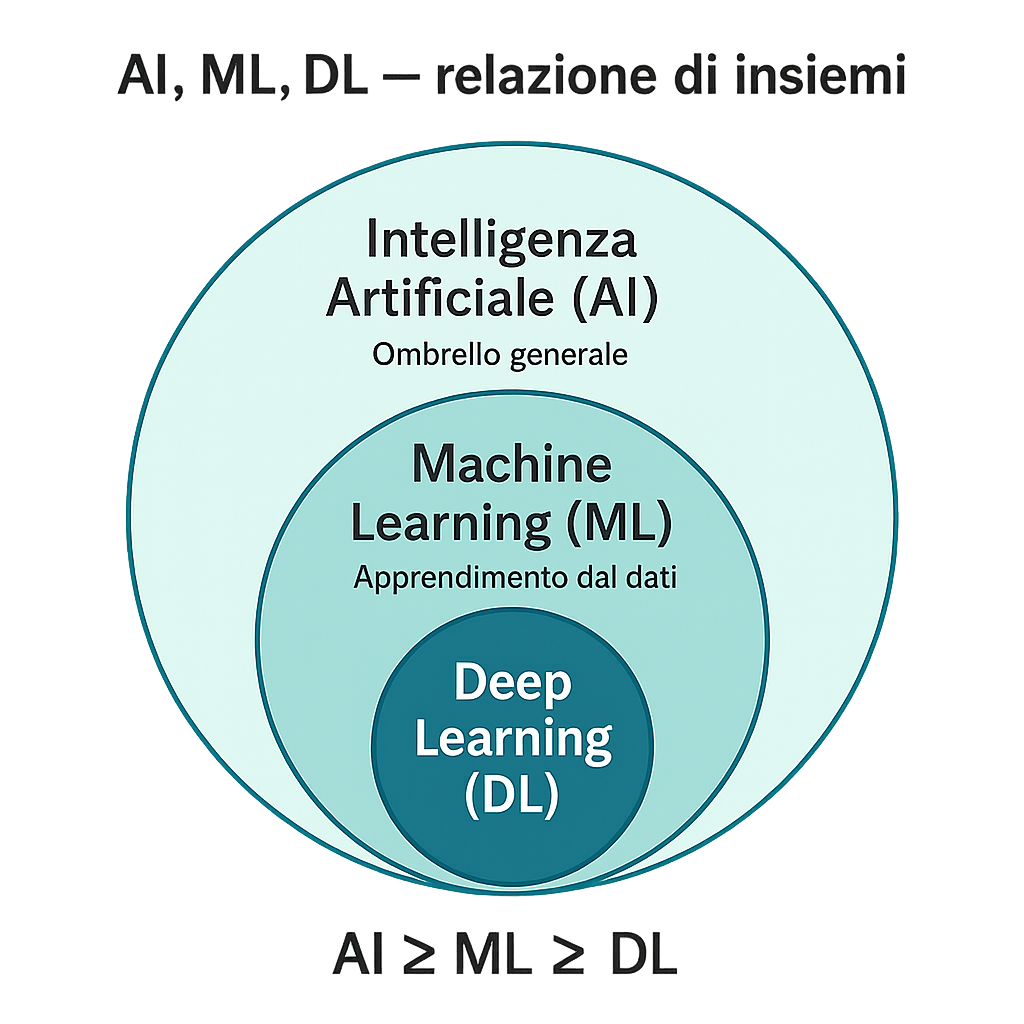
4. In che modo l’AI, il machine learning e il deep learning si differenziano tra loro?
Risposta tecnica:
Intelligenza Artificiale (AI), Machine Learning (ML) e Deep Learning (DL) sono termini correlati ma non equivalenti, con un rapporto di tipo insieme-sottoinsieme. L’AI è l’ombrello più ampio: include qualsiasi tecnica o metodo che permetta a un computer di esibire un comportamento intelligente (dai sistemi basati su regole logiche fino alle reti neurali).
All’interno dell’AI, un sottoinsieme fondamentale è rappresentato dal Machine Learning, che si concentra su algoritmi capaci di apprendere automaticamente dai dati anziché essere programmati con istruzioni fisse.
In altre parole, il ML è quel ramo dell’AI in cui costruiamo modelli statistici che migliorano le proprie prestazioni attraverso l’esperienza, usando metodi come l’apprendimento supervisionato, non supervisionato o per rinforzo. Un esempio di ML: un algoritmo che impara a classificare email come “spam” o “non spam” analizzando migliaia di esempi già etichettati, invece di seguire un insieme rigido di regole definite a mano.
Il Deep Learning è a sua volta un sottoinsieme del machine learning. Si basa su modelli ispirati vagamente alla struttura del cervello umano chiamati reti neurali artificiali a più strati (da cui il termine deep, profondo, che indica molti strati di neuroni artificiali). Invece di richiedere caratteristiche in ingresso definite dall’uomo, le reti di deep learning estraggono automaticamente le caratteristiche rilevanti dai dati grezzi attraverso una gerarchia di livelli di elaborazione.
Ad esempio, in una rete neurale profonda per il riconoscimento di immagini, i livelli iniziali possono rilevare bordi e forme semplici, livelli intermedi possono combinare queste forme in parti di oggetti (come occhi, ruote) e livelli finali riconoscono l’oggetto completo (come un volto o un’auto).
Il deep learning ha avuto un enorme successo negli ultimi anni perché, grazie all’aumento di potenza computazionale e dati disponibili, queste reti profonde hanno superato di molto le prestazioni di approcci ML tradizionali in compiti complessi (visione, linguaggio naturale, gioco, ecc.).
In breve:
- AI è il concetto generale di “macchine intelligenti”;
- ML è un approccio dentro l’AI basato sui dati e sull’apprendimento automatico di modelli;
- DL è una particolare tecnica di ML che utilizza molteplici strati di reti neurali per apprendere rappresentazioni sempre più astratte dei dati.
Una frase celebre in materia è: “Tutto il deep learning è machine learning, ma non tutto il machine learning è deep learning, e tutto il machine learning rientra nell’intelligenza artificiale”.
In parole semplici:
Possiamo immaginare l’AI, il machine learning e il deep learning come matrioske contenute una nell’altra. L’Intelligenza Artificiale è la bambola più grande: è l’idea generale di far fare ai computer cose “intelligenti”.
Dentro l’AI c’è il Machine Learning, che è un modo specifico di ottenere intelligenza artificiale non programmando a mano ogni mossa, ma facendola apprendere dai dati. È un po’ come insegnare a un bambino a riconoscere gli animali mostrandogliene tanti, invece di dargli una lista di regole su forma delle orecchie o lunghezza della coda – ecco, il ML è quel metodo di apprendimento automatico dai dati.
Infine, dentro il machine learning c’è il Deep Learning, che è un metodo particolare ispirato al cervello: usa reti neurali “profonde”, cioè strati su strati di calcoli, che permettono al computer di imparare da solo caratteristiche molto complesse.
Se ML è insegnare al computer con esempi, il deep learning è come dargli un cervello artificiale semplificato con tanti “neuroni” virtuali interconnessi e lasciare che scopra da sé i pattern. Un esempio per chiarire:
- AI: “Voglio che il computer capisca le foto.” (obiettivo generale)
- ML: “Gli faccio imparare a distinguere gatti e cani mostrando milioni di foto già etichettate come gatto o cane.” (approccio per raggiungere l’obiettivo)
- DL: “Uso una grande rete neurale con molti strati che da sola imparerà quali caratteristiche delle immagini distinguono gatti e cani (orecchie a punta? baffi? taglia?) man mano che vede esempi.” (tecnica specifica per implementare il ML)
In sintesi, l’AI è la disciplina (il sogno di macchine intelligenti), il machine learning è una via per realizzare quel sogno (far apprendere i computer dai dati) e il deep learning è la tecnologia all’avanguardia che oggi realizza il machine learning con risultati sorprendenti, imitando in parte il modo in cui funziona il nostro cervello.
5. Perché l’AI è diventata così popolare recentemente, e perché è importante proprio adesso?
Risposta tecnica:
L’AI ha vissuto diverse ondate di interesse, ma l’attuale boom di popolarità è dovuto alla convergenza di quattro fattori principali:
- la disponibilità di enormi quantità di dati digitali (Big Data),
- l’aumento della potenza di calcolo (hardware specializzato come GPU e TPU),
- progressi negli algoritmi, in particolare nel deep learning,
- investimenti e applicazioni industriali che hanno mostrato risultati tangibili.
Negli ultimi dieci anni, la quantità di dati prodotti dall’umanità (testi, immagini, clic web, dati da sensori) è cresciuta in maniera esplosiva, fornendo il “carburante” necessario per addestrare modelli di AI complessi. Allo stesso tempo, i computer sono diventati molto più potenti: in particolare l’uso delle GPU ha accelerato di ordini di grandezza l’addestramento di reti neurali profonde, rendendo fattibile in pochi giorni ciò che negli anni ‘90 avrebbe richiesto secoli di calcolo.
Un punto di svolta spesso citato è il 2012, quando un modello di deep learning (AlexNet) ha stravinto una competizione di riconoscimento di immagini, sfruttando GPU e un grande dataset (ImageNet) – questo ha dimostrato il potenziale dei nuovi algoritmi e ha acceso l’interesse mondiale. Da allora, progressi come le reti neurali convoluzionali per la visione e le reti Transformer per il linguaggio hanno portato l’AI a livelli prima impensabili (ad esempio traduzione automatica quasi istantanea, assistenti vocali accurati, auto a guida autonoma sperimentali, ecc.).
L’AI è dunque diventata popolare perché finalmente funziona davvero bene in molti compiti utili: oggi un algoritmo può battere campioni umani a giochi complessi, diagnosticare malattie da immagini mediche con accuratezza competitiva e così via.
In termini di importanza, adesso è il momento cruciale perché siamo nel pieno di quella che molti chiamano la “trasformazione AI”: l’AI sta rapidamente passando dai laboratori di ricerca all’uso quotidiano in industria, sanità, finanza, intrattenimento, con un impatto economico e sociale enorme. Intere aziende basano il loro modello di business sull’AI (si pensi ai motori di raccomandazione di YouTube, Netflix, Amazon) e governi e istituzioni stanno investendo in AI per non rimanere indietro.
In sintesi, l’AI è sulla cresta dell’onda oggi perché ha raggiunto una maturità tecnica – grazie a Big Data, hardware e algoritmi – e perché le sue applicazioni sono ovunque, dal nostro smartphone ai sistemi aziendali, promettendo aumenti di efficienza e nuove possibilità in quasi ogni settore.
In parole semplici:
Fino a qualche anno fa, l’AI era un po’ come un’auto da corsa senza benzina su una pista sterrata: l’idea era buona, ma mancavano i mezzi. Adesso invece abbiamo tantissima “benzina” (i dati) e l’asfalto liscio (computer veloci) su cui far correre il motore dell’AI. Ecco perché se ne parla così tanto proprio ora. Per esempio: pensa a quante foto scattiamo ogni giorno e quante ore di video carichiamo online – sono una miniera enorme di esempi con cui allenare le AI.
In più, i computer di oggi sono milioni di volte più potenti di quelli di 30 anni fa, quindi possono fare calcoli complicatissimi in pochi secondi. Non solo: gli scienziati nel frattempo hanno migliorato le “ricette” (algoritmi) per far apprendere le macchine.
Quindi l’AI è decollata perché finalmente può ottenere risultati concreti. Ed è importante adesso perché sta cambiando il mondo: con l’AI le automobili iniziano a guidare da sole, i medici hanno uno strumento in più per diagnosticare prima le malattie, i telefoni capiscono la nostra voce, le fabbriche possono ottimizzare la produzione, e così via.
In altre parole, l’AI è diventata una tecnologia chiave come l’elettricità o internet: qualcosa che non era pronta prima, ma oggi sì. E infatti aziende e governi stanno investendo tantissimo: chi sviluppa la migliore AI può risolvere problemi giganteschi e anche guadagnarci (basta pensare a come Google usa l’AI per mostrarci risultati di ricerca più pertinenti, o come Amazon la usa per consigliarci cosa comprare).
Dunque c’è questa combinazione di fattori: più dati, computer più potenti e algoritmi più intelligenti hanno reso l’AI di colpo efficace, e perciò tutti vogliono usarla – ed ecco perché ne senti parlare ovunque proprio adesso.
6. Quali sono i limiti attuali dell’AI? Ci sono compiti che ancora non riesce a svolgere?
Risposta tecnica:
Nonostante i notevoli progressi, gli attuali sistemi di intelligenza artificiale presentano ancora limiti significativi e non sono in grado di svolgere qualunque compito arbitrario. Alcuni limiti principali includono:
- (a) Mancanza di buon senso e contesto generale: gli algoritmi di AI spesso falliscono di fronte a situazioni che richiedono comprensione profonda del mondo reale o ragionamenti di senso comune. Ad esempio, un modello linguistico potente potrebbe generare frasi grammaticalmente corrette ma totalmente prive di senso logico o fattuale, perché non “sa” veramente ciò di cui parla – manca di quella comprensione tacita che gli umani acquisiscono vivendo nel mondo.
- (b) Generalizzazione fuori dal dominio di addestramento: un’AI addestrata su un certo tipo di dati può degradare drasticamente le sue prestazioni se viene applicata a dati troppo diversi (i cosiddetti edge cases o casi limite). Ad esempio, un modello di visione allenato su fotografie in condizioni di luce normali può fallire se l’immagine è sovraesposta, scura o ripresa da un’angolazione inusuale.
- (c) Dipendenza dai dati di addestramento: le AI attuali imparano in modo induttivo dai dati forniti; se questi dati sono scarsi, incompleti o distorti (biased), il modello erediterà questi problemi. Ciò significa che l’AI fatica con compiti per cui non c’è una grande quantità di esempi disponibili o per situazioni completamente nuove mai viste.
- (d) Difficoltà con creatività e trasferimento di conoscenza: i sistemi attuali generano output combinando pattern appresi, ma non sono creativi nel senso umano del termine – ad esempio non hanno vero intuito o capacità di insight originali al di fuori di quello che emerge dai dati di training. Inoltre non sanno trasferire facilmente conoscenze da un contesto a un altro molto differente (cosa che un umano spesso fa).
- (e) Interazione e adattabilità limitata: fuori da compiti ben definiti, un’AI non ha flessibilità generalista. Un robot può navigare un ambiente con una certa programmazione, ma se cambia drasticamente il contesto (metti un robot domestico in una fabbrica) non sarà in grado di adattarsi senza essere riprogettato o riaddestrato.
- (f) Questioni di spiegabilità e controllo: Molti modelli, specialmente di deep learning, sono “scatole nere” e non forniscono spiegazioni trasparenti delle loro decisioni. Questo può portare a errori inattesi difficili da diagnosticare. Un esempio classico di limite è l’incapacità di capire cause e effetti: un’AI può cogliere correlazioni statistiche ma non garantisce di afferrare relazioni causali.
In sintesi, pur essendo potentissimi in domini ristretti, gli algoritmi attuali possono fallire quando escono da quei confini: presentano fragilità ad input anomali (es. adversarial examples), mancano di comprensione contestuale profonda e sono fortemente dipendenti dai dati di addestramento.
La cosiddetta “intelligenza generale” resta un traguardo lontano, e molte capacità che noi diamo per scontate (ad es. capire ironia, avere buon senso pratico, imparare concetti nuovi a partire da pochi esempi) ancora sfuggono alle AI contemporanee.
In parole semplici:
Le AI di oggi sanno fare cose incredibili, ma hanno anche grossi punti deboli. Immagina un super-robot che però ha i paraocchi: è fortissimo nel suo percorso, ma se succede qualcosa di inaspettato fuori da quel percorso, va in tilt. Ad esempio, un’auto a guida autonoma potrebbe guidare benissimo su strade “note”, ma magari davanti a una situazione insolita (come lavori in corso non segnalati) potrebbe non capire cosa fare, perché fuori dalle situazioni per cui è stata addestrata.
Oppure pensa a un assistente virtuale che risponde a tantissime domande: può sembrare quasi umano, ma se gli fai una domanda di buon senso – tipo “puoi mettere un elefante in un frigorifero?” – potrebbe darti una risposta strana, perché gli manca quel buon senso e quella comprensione della realtà che noi umani abbiamo. Le AI non hanno esperienza del mondo, hanno solo visto tanti dati.
Quindi, se la situazione cambia un po’ da quello che hanno visto nei dati, spesso sbagliano. Un esempio concreto: ci sono stati casi in cui un algoritmo di riconoscimento immagini scambiava un segnale di stop stradale per un limite di velocità 45, solo perché c’era sopra un piccolo adesivo (un attacco adversario). Un umano non si farebbe ingannare da un adesivo, capirebbe comunque che è un segnale di stop, ma l’AI no – prende fischi per fiaschi perché ha imparato rigide correlazioni dai pixel.
Inoltre le AI attuali non sanno davvero pensare come noi: non hanno una vera comprensione delle cose, non hanno coscienza o intuito. Se gli chiedi di essere creative, in realtà rielaborano pezzi di quello che hanno già visto. In breve, oggi le AI sono potentissime calcolatrici specializzate, ma se le porti fuori dal loro ambito o chiedi loro qualcosa che richiede flessibilità mentale o ragionamento generale, vanno in difficoltà. Per questo non dobbiamo considerarle infallibili: possono commettere errori banali che un bambino non farebbe, proprio perché non “capiscono” davvero quello che fanno nel senso umano.
7. Come fanno i modelli di AI ad apprendere dai dati senza istruzioni esplicite per ogni caso?
Risposta tecnica:
I modelli di AI imparano dai dati attraverso processi di ottimizzazione statistica che permettono di scoprire regolarità nascoste, anziché seguire regole rigide pre-programmate. Il cuore di questo apprendimento è un algoritmo che adegua iterativamente i parametri interni del modello per migliorare le sue prestazioni.
Prendiamo il machine learning supervisionato come esempio: si fornisce al modello un insieme di dati di ingresso $X$ (ad es. immagini) con le corrispondenti etichette o risultati attesi $Y$ (ad es. categorie di oggetti nelle immagini). Il modello produce delle predizioni $\hat{Y}$ a partire da $X$, inizialmente in modo quasi casuale.
Un funzionale di perdita (loss function) misura l’errore tra le predizioni $\hat{Y}$ e i valori attesi $Y$. A questo punto entra in gioco un algoritmo come la discesa del gradiente stocastica: il modello calcola il gradiente della perdita rispetto ai propri parametri (ad esempio i pesi di una rete neurale) e li aggiusta leggermente nella direzione che riduce l’errore.
Questo ciclo di predizione -> calcolo errore -> aggiornamento parametri si ripete per molte iterazioni (passando attraverso tutti i dati di addestramento, più e più volte) finché l’errore non si abbassa a un livello accettabile. In questo modo, senza che nessuno programmi esplicitamente come risolvere il compito, il modello autonomamente “aggiusta” le sue regole interne per adattarsi ai dati.
Questa è l’idea generale dietro l’apprendimento automatico: il modello contiene migliaia o milioni di parametri inizialmente impostati a valori arbitrari, e l’esperienza sui dati li modella a poco a poco in modo da catturare le relazioni input-output corrette.
Un esempio concreto: in una rete neurale per riconoscere gatti vs cani, durante l’addestramento i primi strati impareranno a rilevare caratteristiche semplici (contorni, macchie di colore), gli strati intermedi combineranno queste caratteristiche in forme più complesse (orecchie, occhi), e gli ultimi strati impareranno a distinguere le combinazioni tipiche di un gatto rispetto a un cane.
Nessuno ha detto al modello “un gatto ha orecchie a punta”, ma mostrando migliaia di immagini e riducendo l’errore pian piano, la rete neurale si configura da sola in modo da attivarsi correttamente quando vede quelle caratteristiche.
Per riassumere: i modelli di AI apprendono trovando pattern statisticamente significativi nei dati. Utilizzano algoritmi di ottimizzazione (come gradiente discendente) per tarare i propri parametri così da replicare le relazioni input-output osservate. Questo consente loro poi di generalizzare a nuovi dati simili, facendo previsioni corrette anche per esempi mai visti prima, basandosi sui pattern appresi durante l’addestramento.
In parole semplici:
Immagina di dover insegnare a un tuo amico a risolvere un puzzle senza mai dirgli le mosse giuste, ma solo dandogli un sacco di tentativi ed evidenziando dove sbaglia. È così che l’AI impara dai dati: per tentativi ed errori guidati. All’inizio l’AI prova a caso o quasi – ad esempio, un sistema per riconoscere immagini può partire facendo predizioni sbagliate. Poi controlla quanto ha sbagliato confrontando con le risposte corrette (questo è l’errore). A quel punto aggiusta un po’ il tiro: modifica leggermente i suoi “ingranaggi” interni (che puoi immaginare come tantissime manopole da regolare) per sbagliare meno la volta successiva.
Ripetendo questo processo milioni di volte, pian piano scopre da sé il modo di ottenere risultati giusti. In pratica, l’AI trova da sola le regole guardando tanti esempi. Ad esempio, come fa un algoritmo a distinguere l’email spam? Gli fai vedere migliaia di email già etichettate come “spam” o “buona”. Ogni volta che ne classifica una male durante l’addestramento, glielo segnali (errore) e lui regola un pochino i suoi parametri interni.
Dopo tantissimi aggiustamenti, alla fine ha “capito” che certe parole, certi schemi di testo (tipo “VINCI PREMIO!!!” in maiuscolo) compaiono spesso nelle spam, e userà queste scoperte per il futuro. Il bello è che nessuno ha scritto nel codice “se vedi ‘VINCI PREMIO’, segna spam”: è il modello che l’ha dedotto da solo perché quell’indizio contribuiva ad abbassare l’errore nelle prove passate.
Dunque l’AI impara come un bambino che sbaglia e corregge: prova, confronta col risultato giusto, corregge la propria strategia e riprova finché non diventa bravo. Dopo l’addestramento, quando vede qualcosa di nuovo, può dire: “Ah, questo assomiglia agli esempi che ho visto prima, quindi probabilmente devo comportarmi in questo modo.” Ecco come fa l’AI a cavarsela senza che qualcuno le abbia dato istruzioni per ogni singolo caso: ha estratto lei le regole generali dagli esempi passati.
8. Cosa distingue l’automazione basata su regole dagli approcci moderni guidati dall’AI?
Risposta tecnica:
L’automazione tradizionale basata su regole (anche detta programmazione esplicita o rule-based systems) si fonda su un insieme di istruzioni logiche ben definite dall’uomo: il programma segue percorsi if-then (se-condizione-allora-azione) decisi a priori.
Ad esempio, un sistema a regole per classificare email spam potrebbe contenere regole fisse come: “SE l’oggetto contiene la parola ‘gratis’ E il mittente non è nella rubrica, ALLORA classifica come spam.” Questi sistemi funzionano bene in scenari ristretti e completamente prevedibili, ma diventano rigidi e difficili da scalare man mano che le situazioni possibili aumentano, poiché richiederebbero di enumerare manualmente tutte le regole.
Gli approcci moderni di AI, al contrario, non seguono regole pre-scritte caso per caso, ma imparano un modello dai dati. Invece di decidere a tavolino ogni condizione, si forniscono al sistema molti esempi e un algoritmo di apprendimento fa emergere da quei dati le correlazioni e pattern utili per svolgere il compito.
Tornando all’esempio del filtro anti-spam: un modello di AI (ad es. un classificatore bayesiano o una rete neurale) analizza statisticamente i termini, la struttura del testo, il formato delle email etichettate come spam vs legittime, e deriva un proprio insieme di “regole” probabilistiche interne, ad esempio che la parola “gratis” combinata con certe altre caratteristiche porta a X% di probabilità di spam. Nessuno ha codificato esplicitamente questa regola: è il risultato dell’ottimizzazione sui dati storici.
Dunque, la differenza cruciale è che nell’approccio AI il comportamento viene appreso, mentre nell’approccio basato su regole il comportamento viene programmato. Questo comporta che le soluzioni AI tendono a essere più flessibili e ad adattarsi meglio a variazioni non previste (entro certi limiti), poiché hanno generalizzato dai dati, mentre i sistemi a regole sono letterali: se incontrano un caso leggermente diverso da quelli previsti, potrebbero non gestirlo affatto.
Ad esempio, un chatbot a regole risponde solo a frasi esatte o molto vicine a quelle previste nei suoi script, mentre un chatbot basato su AI può capire e rispondere a formulazioni di domande mai viste prima, perché ha appreso il linguaggio in generale.
In sintesi: nell’automazione classica il know-how risiede nel programmatore che codifica regole statiche, nell’AI il know-how risiede nei dati e nell’algoritmo che li modella. Questa differenza rende gli approcci AI estremamente potenti in domini complessi (linguaggio naturale, visione artificiale, etc.), dove elencare manualmente tutte le regole sarebbe impraticabile.
In parole semplici:
La differenza tra un sistema a regole e uno basato su AI si può paragonare alla differenza tra seguire una ricetta e imparare a cucinare assaggiando e sperimentando. Un sistema tradizionale a regole ha una lista precisa di istruzioni: se succede A fai B, se succede C fai D, punto.
È come una macchina molto rigida: fa esattamente quello che il programmatore ha deciso in anticipo. Immagina di dover far riconoscere a un computer le email di spam con regole: dovresti tu pensare a tutte le caratteristiche possibili delle spam (parole sospette, formattazioni, mittenti strani) e scrivere una regola per ognuna. Ma se arriva una spam un po’ diversa da quelle previste, il sistema a regole non la riconosce, perché fuori dallo schema predefinito. L’approccio AI invece è più elastico: è come dire al computer “impara tu dagli esempi quali sono le spam”.
Quindi al posto di scrivere mille regolette, gli fai vedere magari 100mila email già classificate e il computer trova da solo i segnali tipici delle spam (magari noterà che lo spam spesso contiene molte immagini e poche parole, o certe frasi come “hai vinto”). Così, se arriva una nuova email, anche se non rientra perfettamente in nessuna regola esplicita scritta, l’AI può riconoscerla come spam perché statisticamente somiglia alle spam che ha visto durante l’apprendimento.
In pratica, l’automazione a regole è rigida: funziona tipo “se accade X fai Y” (e oltre non va). L’AI invece è adattabile: funziona tipo “ho visto tanti X e Y e ho capito come correlarli, quindi se vedo qualcosa di simile a X farò una cosa simile a Y”. Un esempio semplice fuori dall’informatica: immagina un assistente clienti telefonico. Quello tradizionale a tasti (“premi 1 per saldo, 2 per assistenza tecnica…”) segue regole fisse.
Uno moderno con AI potrebbe farti parlare liberamente e capisce dalle tue parole cosa vuoi, anche se usi frasi non previste. Insomma, nelle soluzioni basate su AI il sistema impara da solo e quindi può affrontare meglio casi nuovi; in quelle a regole fa solo ciò che è stato programmato e basta.
9. Quando e come è nata l’intelligenza artificiale come campo di studi?
Risposta tecnica:
Il concetto di “macchine pensanti” ha radici nella metà del Novecento, ma la nascita ufficiale del campo dell’Intelligenza Artificiale come disciplina viene fatta risalire al 1956, anno in cui si tenne il famoso Dartmouth Workshop.
In quell’estate del 1956, un gruppo di ricercatori (tra cui John McCarthy, Marvin Minsky, Claude Shannon e altri) si riunì al Dartmouth College (USA) per un progetto di ricerca estivo in cui coniarono il termine “Artificial Intelligence”. John McCarthy è accreditato per aver proposto proprio l’espressione “intelligenza artificiale” in quella occasione.
Lo scopo dell’incontro era esplorare l’idea che “ogni aspetto dell’apprendimento o qualunque altra caratteristica dell’intelligenza possa, in linea di principio, essere così descritto con precisione da poter essere simulato da una macchina”. Prima di Dartmouth, c’erano già stati importanti passi preparatori: nel 1950 Alan Turing pubblicò l’articolo “Computing Machinery and Intelligence” in cui introdusse il famoso Test di Turing come criterio per valutare l’intelligenza di una macchina.
Negli anni ‘40 e ‘50 c’erano stati anche sviluppi della cibernetica e primissimi modelli computazionali di neuroni (come quelli di McCulloch e Pitts nel 1943). Ma è dopo il workshop del 1956 che l’AI decolla come campo autonomo: i decenni successivi videro la nascita di programmi pionieristici, come Logic Theorist (1956) di Newell e Simon – considerato il primo programma AI, capace di dimostrare teoremi – e General Problem Solver (1957). Gli anni ’60 videro l’interesse militare (progetti come Shakey, il primo robot mobile intelligente) e la fioritura di diversi approcci (sistemi simbolici e reti neurali iniziali).
In breve, l’AI nacque formalmente a Dartmouth nel 1956, coniando il nome e delineando l’ambizioso obiettivo di simulare l’intelligenza.
Da allora, la storia dell’AI ha avuto alti e bassi (i cosiddetti “AI winter” negli anni ‘70 e fine ‘80 per delusioni rispetto alle aspettative e tagli di fondi, seguiti da nuove ondate di successo come quella attuale). Oggi guardiamo a quell’evento del 1956 come l’atto di nascita ufficiale, anche se naturalmente le idee e i primi rudimenti hanno radici leggermente anteriori (Turing 1950, Wiener e la cibernetica, ecc.) e gli sviluppi pratici si sono susseguiti per decenni fino ai risultati straordinari odierni.
In parole semplici:
L’idea di intelligenza artificiale ha circa sessant’anni di storia. Possiamo dire che è nata in un momento preciso: un incontro di studiosi nell’estate del 1956 al Dartmouth College, negli Stati Uniti.
Fu lì che per la prima volta si usò proprio l’espressione “intelligenza artificiale” per definire un nuovo campo di ricerca. Era un piccolo gruppo di scienziati molto visionari (tra cui John McCarthy, che inventò il termine, e Marvin Minsky) che credevano di poter far “pensare” i computer.
Possiamo immaginare quel workshop come la “culla” dell’AI: prima c’erano idee nell’aria (ad esempio Alan Turing nel 1950 aveva già scritto di macchine intelligenti e proposto il suo test, ma lì a Dartmouth decisero ufficialmente di fondare una disciplina che provasse a costruire macchine intelligenti.
Nei primi anni, fine ’50 e ’60, gli entusiasti dell’AI svilupparono i primi programmi che risolvevano problemi logici o giocavano a dama. Erano molto semplici rispetto a ciò che abbiamo oggi, ma per l’epoca erano sorprendenti. Ad esempio, nel 1956 un programma chiamato “Logic Theorist” riuscì a dimostrare alcuni teoremi di matematica – cosa impensabile fino a pochi anni prima!
Quindi la risposta breve: l’intelligenza artificiale come campo di studi è nata intorno alla metà degli anni Cinquanta, formalmente con quell’incontro nel 1956 che fissò l’idea che le macchine potessero un giorno imparare e ragionare come esseri umani. Da lì è iniziato un lungo viaggio: ci sono stati periodi di grande ottimismo e altri di delusione (negli anni ’70 e ’80 la ricerca rallentò un po’ per risultati sotto le aspettative), ma poi con più potenza di calcolo e nuove idee è tornata a esplodere.
Così, se oggi abbiamo assistenti vocali e auto intelligenti, lo dobbiamo a quel seme piantato nel 1956 a Dartmouth.
10. L’AI pensa davvero come un essere umano? In che cosa l’intelligenza artificiale differisce da quella umana?
Risposta tecnica:
L’AI attuale non “pensa” come un umano nel senso stretto: i suoi meccanismi interni sono molto differenti dai processi cognitivi biologici, e soprattutto manca di coscienza, intenzionalità e comprensione profonda. Dal punto di vista computazionale, un’AI elabora informazioni attraverso calcoli matematici su dati numerici (ad esempio propagando numeri in una rete neurale), individuando correlazioni statistiche.
Il cervello umano, invece, funziona con neuroni biochimici e trasmissioni elettriche che danno origine a fenomeni come la coscienza soggettiva, le emozioni, l’intuizione – elementi che un’AI non possiede. Una differenza chiave è che gli algoritmi di AI non hanno esperienza del mondo fisico: conoscono ciò per cui sono stati addestrati, ma non hanno un corpo, non provano bisogni, non hanno evoluzione biologica. Questo implica che mancano di buon senso e di comprensione contestuale ampia che gli umani acquisiscono vivendo.
Ad esempio, un bambino sa istintivamente che una stessa persona vista da dietro è ancora quella persona: l’AI deve impararlo da molti dati e potrebbe comunque confondersi in casi limite. Inoltre, l’intelligenza umana è adattiva e generale: di fronte a una nuova situazione, un umano può ragionare analogicamente o per esperienza e improvvisare soluzioni.
L’AI (debole) è invece legata al suo dominio specifico; se la porti fuori contesto, fallisce. Un altro aspetto è la creatività e intenzionalità: gli esseri umani possono avere idee originali e soprattutto hanno intenzioni proprie, volontà. Un’AI generativa può scrivere un testo creativo, ma lo fa mescolando in modo sofisticato ciò che ha visto nei dati, senza intendere realmente un messaggio o provare emozioni in quello che scrive.
Dal punto di vista neurologico, la distanza è enorme: ad esempio, i modelli di deep learning hanno milioni (o miliardi) di parametri che vagamente corrispondono a connessioni neurali, ma il cervello umano ha circa 100 miliardi di neuroni con complessi cicli biochimici – le scale e architetture non sono paragonabili direttamente. In sintesi, l’AI di oggi simula alcuni comportamenti intelligenti (percepisce input e produce risposte corrette) ma senza replicare i processi mentali umani sottostanti.
La mancanza di autocoscienza e di autentica comprensione semantica è un distinguo fondamentale: un’AI può elaborare la frase “il cielo è blu” e risponderci, ma non sa davvero cosa sia il cielo o il colore blu come esperienza. Come evidenziato spesso in letteratura (Searle, Chinese Room), l’AI manipola simboli senza semantica: per noi mente umana quei simboli hanno significato, per la macchina sono pattern di bit manipolati secondo regole statistiche.
Finché non emergeranno scoperte radicali, possiamo dire che l’intelligenza artificiale è un’imitazione computazionale di alcune funzioni dell’intelligenza, ma non è equivalente all’intelligenza umana né per meccanismi né per ampiezza di capacità.
In parole semplici:
Oggi come oggi, i computer anche i più “intelligenti” sono un po’ come pappagalli molto avanzati: possono sembrare che parlino e pensino, ma in realtà non capiscono davvero quello che dicono. L’intelligenza umana è fatta non solo di calcoli, ma anche di esperienza del mondo, di emozioni, di coscienza di sé (cioè noi sappiamo di esistere, i computer no).
Quando un’AI risponde a una domanda, lo fa perché ha visto tantissimi esempi simili e sta essenzialmente tirando fuori un risultato sulla base di quelle statistiche – non perché abbia compreso come noi comprenderemmo.
Ad esempio, ChatGPT può darti un consiglio su come coltivare le rose, ma non ha mai visto una rosa, non sente il profumo, non sa cosa significhi davvero sporcarsi le mani di terra: sta solo usando quello che ha letto nei testi.
Un bambino, anche se non ha letto centinaia di libri, ha quella comprensione fisica ed emotiva del mondo (sa che se si punge con una spina, fa male; sa che deve annaffiare una pianta altrimenti appassisce perché ha visto accadere). L’AI queste cose non le ha. Inoltre, noi umani abbiamo un’intelligenza “tuttofare”: la stessa mente che risolve un problema di matematica può anche suonare il piano o capire una barzelletta. Ogni AI invece ha un compito ristretto: l’AI che gioca a scacchi sa giocare a scacchi e basta, non può scrivere una poesia o cucinare una torta.
Un’altra grossa differenza è che noi abbiamo motivazioni e creatività spontanea, un computer no.
Tu potresti svegliarti con l’ispirazione di dipingere qualcosa di nuovo – un computer genererà un dipinto solo se gli viene chiesto e comunque attingendo a ciò che ha già visto. Insomma, il cervello umano è incredibilmente complesso e ancora in parte misterioso, fatto di neuroni veri che sentono stanchezza, rilasciano ormoni, sognano la notte…
Un’AI è fatta di chip di silicio che eseguono operazioni matematiche su numeri. Per quanto possano simulare alcuni comportamenti, manca tutta la parte “viva” dell’intelligenza. Quindi, no, l’AI non pensa come un essere umano. Può risolvere problemi e prendere decisioni in modo simile in certi casi, ma non ha coscienza, non capisce con il senso comune, e non prova nulla.
È un po’ come la differenza tra un robot che dice “ti amo” perché è programmato per farlo e una persona che lo dice provando davvero amore: la frase è uguale, ma il robot non sente niente, segue solo un copione. Allo stesso modo, dietro le quinte l’AI fa calcoli, non ragionamenti ed esperienze come i nostri.


